Recap: Linear Classifier
\[
f_{W,b}(x)=\underbrace{W}_{10\times 3072}\quad \underbrace{x}_{3072\times 1}+\underbrace{b}_{10\times 1}
\]

Problem: Linear Classifiers are not very powerful
Linear classifiers only work when data points are
Examples of linearly separable versus linearly non-separable:
linearly separable.
Examples of linearly separable versus linearly non-separable:
linearly separable
linearly non-separable
Motivation of Feature Extraction

Image Feature Extraction

Hierarchical Computation
2-layer Neural Network: $f=W_2\max(0, W_1x)$

- All dimensions of $h$ are computed from all dimensions of $x$; and all dimensions of $s$ are computed from all dimensions of $h$.
- $W_1$ and $W_2$ are also called fully-connected layers (FC layers), and the network is also called a multi-layer perceptron (MLP).
Activation Functions

ReLU is a good default choice for most problems
Example Feed-Forward Computation
of a Neural Network

[REPLACE BY A TORCH CODE SNIPPET]
# forward-pass of a 3-layer neural network:
f = lambda x: 1.0 / (1.0 + np.exp(-x)) # activation function (use sigmoid)
x = np.random.randn(3, 1) # random input vector of three numbers (3x1)
h1 = f(np.dot(W1, x) + b1) # calculate first hidden layer activations (4x1)
h2 = f(np.dot(W2, h1) + b2) # calculate second hidden layer activations (4x1)
out = np.dot(W3, h2) + b3 # output neuron (1x1)
Full Implementation of Training a Neural Network
[REPLACE BY TORCH CODE]

Decision Boundaries of Linear Classifiers
- Let us first restrict the discussions to binary classification
- Recall that, the decision boundary of a linear classifier can only be straight lines.
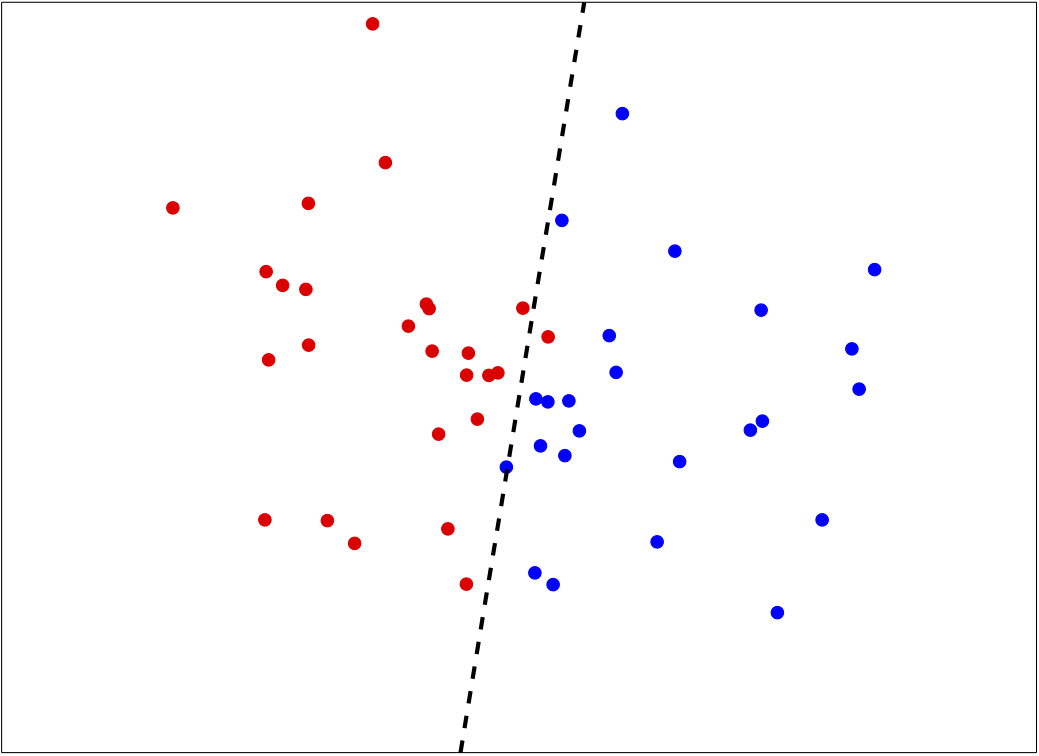
Decision Boundaries of Neural Networks
Consider the 2-layer neural network:
\[
f_{W_1, W_2}(x)=W_2\max(0,W_1x),
\]

Decision Boundaries of Neural Networks
- We are able to create a very complex decision boundary by even a 2-layer neural network
- In the following example, all the training data will have correct label predictions with 20 hidden neurons
